Does your organization have an army of data entry operators who are manually entering data to your systems by looking at PDF or Word documents?
What if there is a way to automate the process while saving time and money?
What to Explore
Structured, Semi-Structured and Unstructured Data
Data is required to study various trends, reports, understand “how the business is going” and is essential for decision making. There is a trend toward developing models that help with predictions, such as artificial intelligence (AI) and machine learning (ML). However, data is required to train models to implement AI and ML, therefore, businesses have departments responsible to capture data. This data that we are referring to primarily sits in three structures: structured, semi-structured and unstructured.
- Structured Data is data that has a well-defined structure. The name and data type of each column is defined. This type of data is tractable. An example of structured data is SQL tables.
- Semi-Structured Data shares some similarity with structured data in that the structure of the data is defined along with flexibility to add and/or skip fields from any record. This type of data is tractable. Examples of semi-structured data include JSON files and XML files.
- Unstructured Data is data that has no structure (no surprises here) and therefore is not tractable. Examples of unstructured data include Word documents, PDF files and scanned images.
Problems of Unstructured Data in the Organization
In most organizations, a large amount of data is unstructured. This unstructured data is present in Word documents, PDF files and so forth. To build AI/ML models and reports, the unstructured data needs to be converted into structured (or semi-structured) type of data. To perform this conversion, there are armies of data entry operators who read through those documents and manually enter them into respective systems which accept structured data.
Since the volume of the data is immense, there is a high probability of errors like typos, missed fields and/or missed entries. These errors can lead to incorrect models, misleading reports and trends. Additionally, the unstructured data contain a lot of noise (i.e. unnecessary fields or data like privacy policies, disclaimers etc.) which increases the chances of error. Furthermore, the time for manual conversion from unstructured to structured type can take days or weeks, or may even be months depending upon team velocity and volume of work.
To illustrate, we can discuss a situation where a company with multiple subsidiaries sends their invoicing data to the parent company in the form of PDFs (one file per invoice). The parent company captures few fields from each invoice and saves it to their data warehouse for further analysis. These invoices are received on a shared mailbox. Since there are multiple people reading the mailbox, there is a possibility of duplicate entries or missed entries which result in inaccurate data in warehouse. All such inaccuracies could easily be avoided through automation. The format of invoice barely changes, thereby making it feasible to write a script that can automate the process.
Options to Automate Data Extraction
Form Recognizer
A possible solution to the problem is to use services provided by leading cloud providers. One such solution is the Form Recognizer under Azure Cognitive services that takes a file as input and gives outputs in key value pairs. A few blank forms can be uploaded to train the model and then use the model to extract the data. This is a swift and simple process. The tool works great with simple forms, however, some shortcomings are evident while processing complex forms.
Other potential options from leading cloud providers include Google Cloud Vision and AWS Textract.
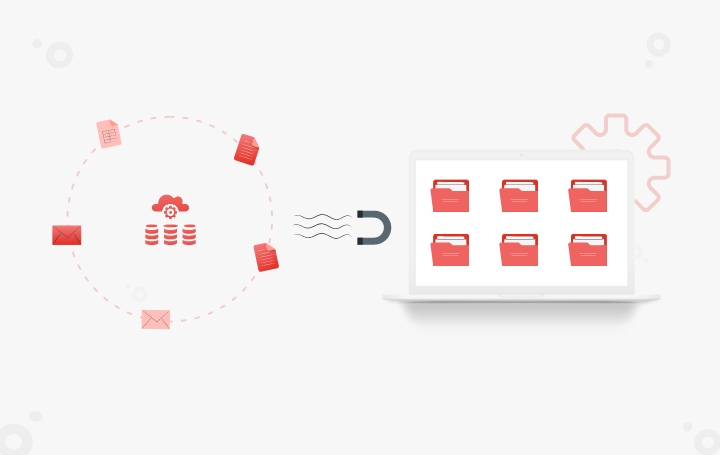
Template-Based Extraction
In template-based extraction method, boundaries, anchors and rules (i.e. regular expression rules to make sure we are reading the right pattern) are defined to extract each field. Alternatively, a ML model can be trained to perform the extraction. In addition, a set of validation rules is created to ensure accurate extraction. In case any validation rule is violated, the record is flagged. Later, flagged records are verified and/or corrected before submission.
The below table provides a comparison of Form Recognizer and Template-Based Extraction methods with considerations for noise, flexibility and accuracy, and validation.
| Form Recognizer | Template-Based Extraction | |
| Noise | The tool tries to convert the whole document into key value pairs and most of the documents are not formatted that way. If a lone field is found, the tool treats that field as a key with empty value which adds noise. | Only the required fields are extracted therefore discarding all the noise. |
| Flexibility & Accuracy | The tool reads the document as per its understanding from the model. If the dataset used to train the model is not adequately diverse, the extraction can flawed. | Flexibility to train a model or define boundaries, anchors, and rules for extraction. In cases where insufficient data is available for model training, alternate ways are available to improve accuracy. |
| Validation | No direct way to configure validations and an extra layer needs to be built for validations. | The validation rules are built into the template. |
Data Extraction Case Study
Working with a Fortune 500 Insurance company, Bitwise recommended and implemented a template-based extraction solution to process 10,000 policies from a single year. Through this process, more advantages to automation were identified than expected. In addition to automation, gaps in the process were surfaced, and hence remediated.
Key findings from this engagement include:
- Accuracy – The accuracy of template-based extraction was close to 90% and remaining 10% were properly flagged for manual verification.
- Record Completion & Typos – On auditing the data captured by data entry operators, typos, incomplete and incorrect records were found in about 5% of policies.
- Identifying Non-Compliance – A couple of nonconformist agents were identified and were notified about the issue.
- Data Quality – Some fields were incorrectly accepted by data entry operators and correctly flagged by the automated script (for example – P.O. Box numbers in place of addresses).
Other advantages of template-based solution:
- Cost Effective – As template design is the core of the system, it takes the lion’s share of the cost. Once the template is ready, processing is economical. On the other hand, for Form Recognizer (and other tools from leading cloud providers), the setup is inexpensive whereas the processing is expensive. Users are charged for processing documents whether it was successful or not.
- Flexible – The process is owned by the company and the company has flexibility to run on-premise or cloud environment as per their needs. In scenarios where companies need to keep the document in their own network and cannot load it to cloud or other networks, this method comes handy.
- Easy to Integrate – Can be easily integrated with an on-premise or cloud workflow. Since the companies have ownership, it can be easily adjusted to integrate with any other processes, workflows or systems.
Read the full data extraction case study.
Conclusion and Next Steps
Accurate data on analysis provides information, and that information is useful in taking decisions for the future of the organization. Therefore, if a company has a large amount of unstructured data sources, it is wise to automate that process using template-based extraction instead of trying to capture it manually. It is not just about the accuracy, speed and quality of data that is captured, it is also about utilizing resources toward functions that cannot be automated. The solution relates to stepping alongside our technological evolution.
Contact Us if you are in a similar situation and looking for a solution to implement an automated process. Bitwise team can help recommend and implement an optimal solution customized to your specific requirements on-premise, in the cloud or even a hybrid environment.
Recommended Content

You Might Also Like

Data Security
Implementing Fine-Grained Data Access Control: A Complete Guide to GCP Column-Level Policy Tags
Learn More