Data Governance
Implementing Fine-Grained Data Access Control: A Complete Guide to GCP Column-Level Policy Tags

What to Explore
What you will learn
- Fundamentals of Fine-Grained Data Access Control
- Learn how to implement GCP column-level security using policy tags and data masking rules
- Understand best practices for taxonomies and inheritance structures
- Discover automated approaches to policy tag management
- See real-world examples of fine-grained access control
The Challenge
As organizations scale, implementing data governance becomes more complicated, especially when cross functional teams from marketing, finance, product and sales work on data initiatives. Increasing use of artificial intelligence, machine learning and now generative AI, makes it even more difficult as legal teams require transparency and scrutiny while data is being accessed by the different teams.
Companies that manage data are facing a big challenge. They need to share important business information with the right people, but they also have to keep sensitive data safe.
This sensitive data includes things like:
- Personally Identifiable Information (PII): Social Security numbers, tax IDs, addresses, emails, passwords, etc.
- Financial information: Bank account numbers, financial statements, etc.
- Medical information: Diagnoses, treatment records, etc.
The old way of controlling who sees what data is too simple. It’s like putting a big lock on a whole table in a library, instead of locking individual books. This can let people see things they shouldn’t.
As companies deal with more and more complicated data, they need a much better way to control who can access what. This is called ‘granular access control’ and it’s becoming essential for keeping data safe.
Here are some statistics from IBM and Verizon’s 2024 data breach reports:
- The staggering financial impact of data breaches reached a global average of $4.88 million!
- The most common type of data stolen or compromised was customer PII, at 46%. And it can be used in identity theft and credit card fraud.
- The majority (around 62%) of data breaches are financially motivated.
- A significant increase in data breaches compared to previous years.
In my role as a Data Engineer at a leading fintech organization, I encountered significant data governance challenges while managing a petabyte-scale data warehouse. Our team was tasked with implementing comprehensive PII data protection across an extensive data ecosystem comprising over 10,000 tables and 1,000+ ELT processing jobs.
The project presented two critical challenges that required careful consideration and strategic planning:
- Implementing robust data security measures while ensuring zero disruption to existing data products and maintaining seamless service for our customers.
- Developing an efficient methodology to discover and classify sensitive data across thousands of tables, followed by implementing appropriate redaction and encryption protocols based on defined sensitivity rules.
The scale and complexity of this undertaking was particularly noteworthy given our active data warehouse environment, which required maintaining business continuity while enhancing security protocols.
The Solution: Column-Level Policy Tags in GCP
What Are Policy Tags?
Policy tags in Google Cloud Platform provide a hierarchical system to define and enforce access controls at the column level. Think of them as intelligent labels that:
- Define security classifications for data
- Inherit permissions through a taxonomy structure
- Integrate with IAM roles and permissions
- Enable dynamic access control
These policy tags are managed using taxonomies in BigQuery. A Taxonomy in BigQuery acts like a hierarchical container system that organizes your policy tags – think of it as a secure file cabinet where each drawer (category) contains specific folders (policy tags) for different types of sensitive data.
These policy tags are then attached to specific columns in your BigQuery tables to control who can see what data. Dynamic data masking on policy tags allows setting up different masking rules for different roles based on their needs. Such as redaction,nullification or custom user defined function without actual data modified in the table.
For example, a “PII_Taxonomy” might have categories like “High_Sensitivity” containing policy tags for Government IDs and social security numbers, while “Medium_Sensitivity” could contain tags for email addresses and phone numbers.
To solve our challenges, we used policy tags to attach to sensitive data fields and then manage permissions at tag level. This provided us flexibility to implement role based access controls (RBAC) without disrupting any table data, or its end users. See the below flow chart for high level steps.
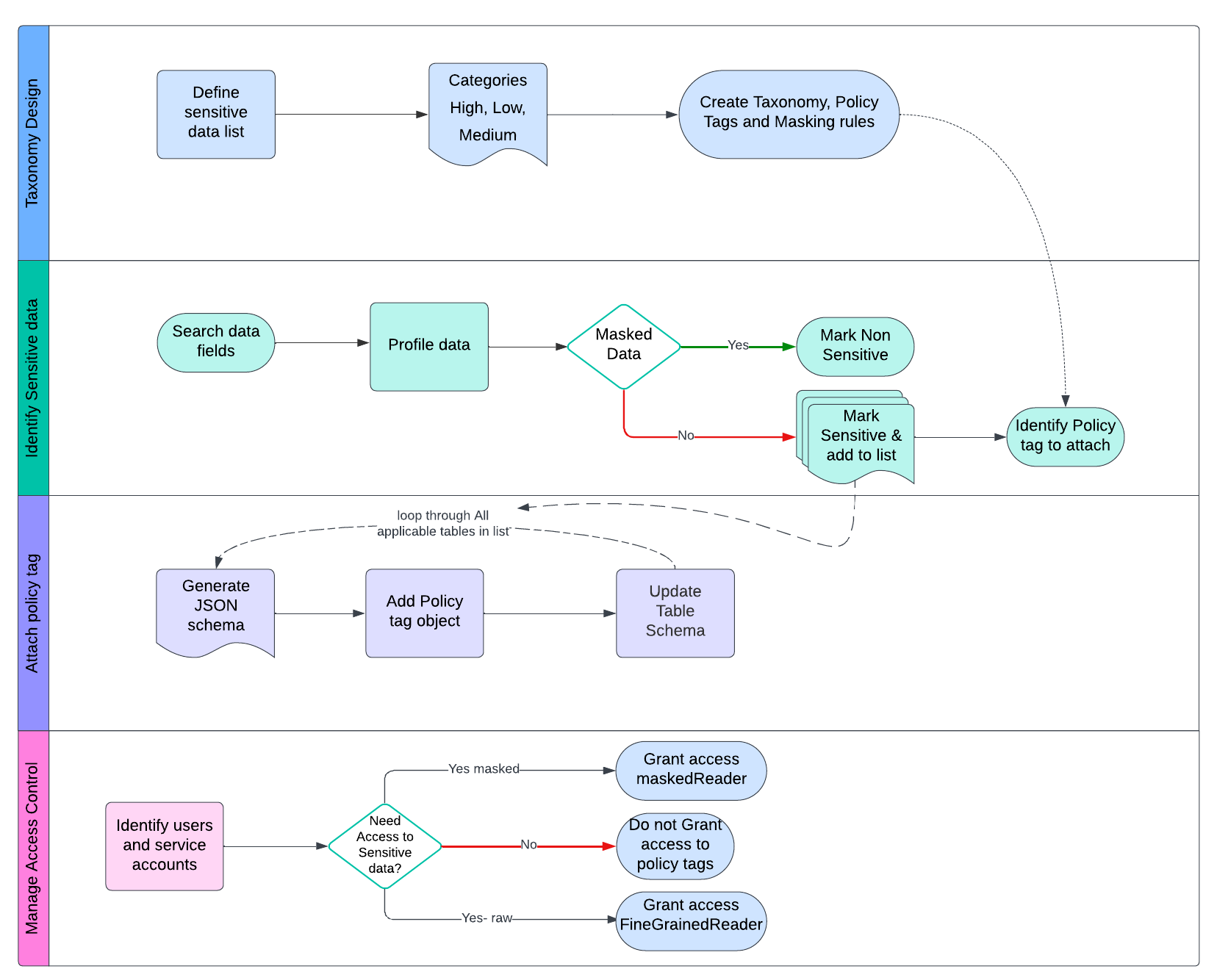
With legacy domain understanding and subject matter experts, we defined a list of sensitive data that can be ingested into a data warehouse. We then categorized the list based on compliance and legal terms, as to what are high severity sensitive data fields, low and medium, and their consumption patterns. And used it to create our hierarchical taxonomy structure. See for detailed steps and commands to create taxonomy structure in the implementation guide below.
Then we created a program that identified sensitive data fields and also profiled sample data to confirm its sanity. It also identified what policy tags to attach to a data field. This program gave us a matrix of Table, Column and Policy tag that it needs to be attached.
Then we came up with our final program that actually attached policy tags to tables using bq command line tools such as bq schema to get the latest structure of the table, add policy tags to it and use bq update to attach policy tags to tables in BigQuery.
Because there were 10000+ tables, we released the changes in phases instead of one big bang.
Implementation Guide
Let’s create a taxonomy that categorizes PII sensitive data by severity. Each category can have sub-categories for specific policy tags to be applied to table columns. Refer to the diagram below:
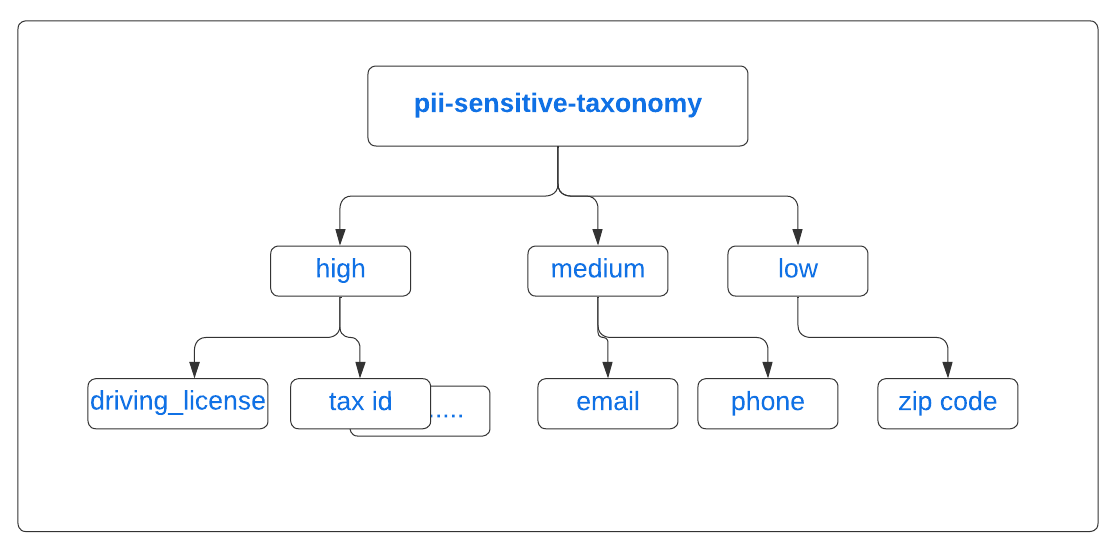
Step 1: Create taxonomy with parent Policy tag ‘high’ and its child tag ‘driving_license’ as described in above diagram:
- Refer this python code from this Jupyter notebook for step by step execution create_taxonomy_and_data_masking
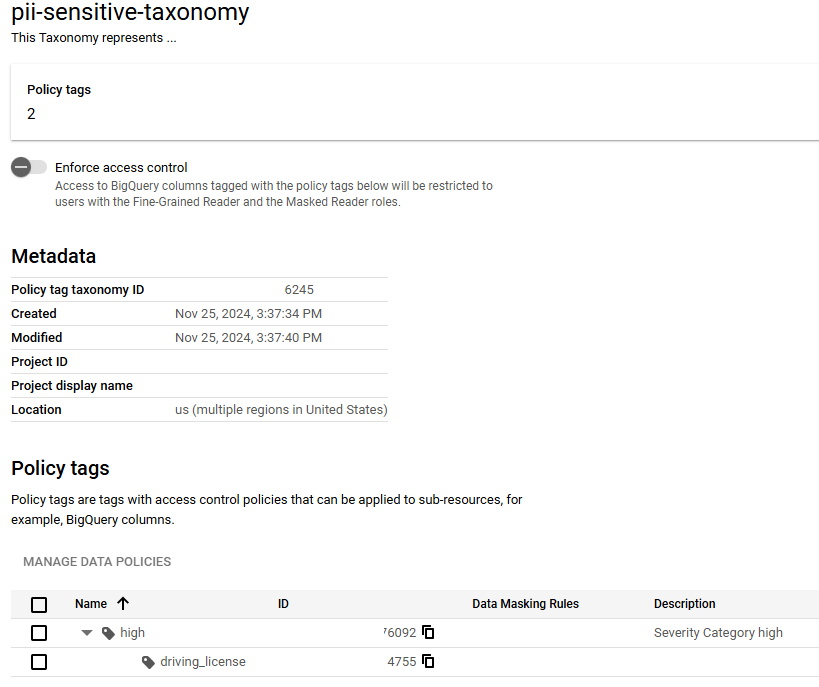
- After executing the code you should see a taxonomy and policy tag structure as below
- Repeat the same process to create medium and low category and sub-tag for all required tags.
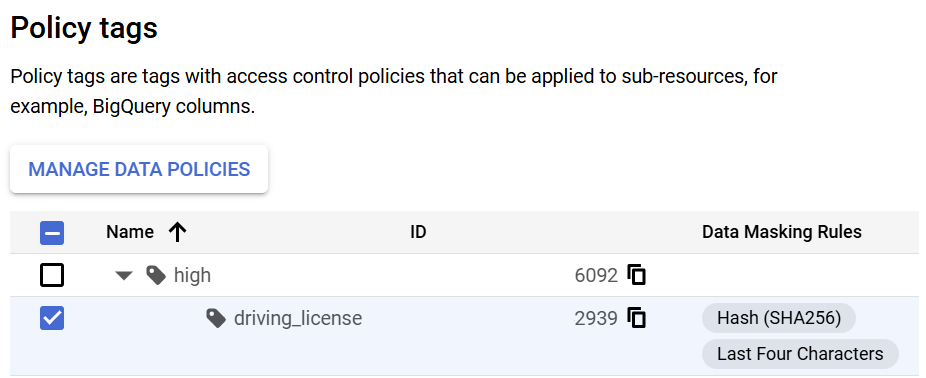
Step 2: Create data masking rules for policy tag driving_licence
- Let’s create 2 different masking rules for different teams such as below
- One for sales team who needs to see only last 4 chars of driving licence
- Another for analytics team who do not need to see the original value but unique hash for each distinct data value
- Follow the steps in Jupyter notebook to create these.
- Once you are done with these you can see the masking rules to your policy tag as below in your policy tag console.
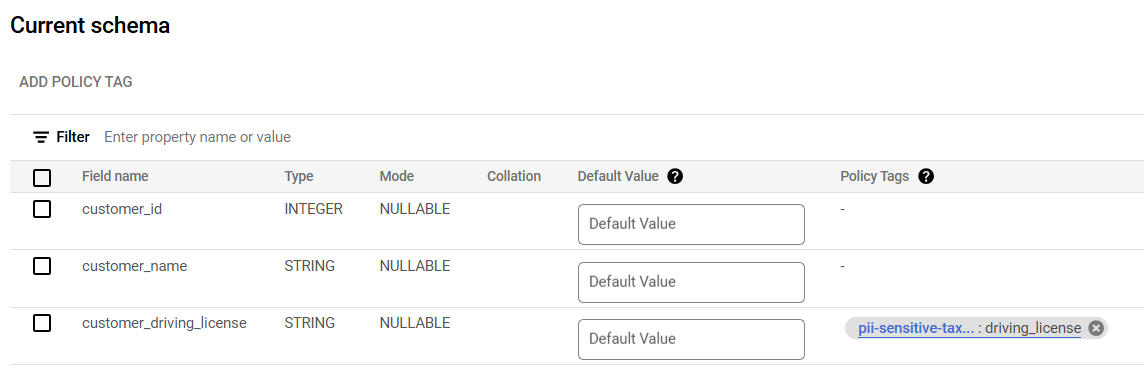
Step 3: Apply Policy Tags to the Columns with appropriate sensitive data
- Run bq commands on command-line to attach policy tag to your table
- Refer commands here – attach_policy_tag_to_column.sh
- After applying the tag you should be able to see it in Bigquery console table schema
Step 4: Assign IAM Permissions to enable access control, first provide necessary permissions to applicable users.
- Assign roles/bigquerydatapolicy.maskedReader to your sales user on pii_last_four masking rule
- Assign roles/bigquerydatapolicy.maskedReader to your analytics user on pii_hash masking rule
- Assign roles/datacatalog.categoryFineGrainedReader to your users who need to access the raw data
- Refer set_permissions.sh for gcloud commands and follow notebook
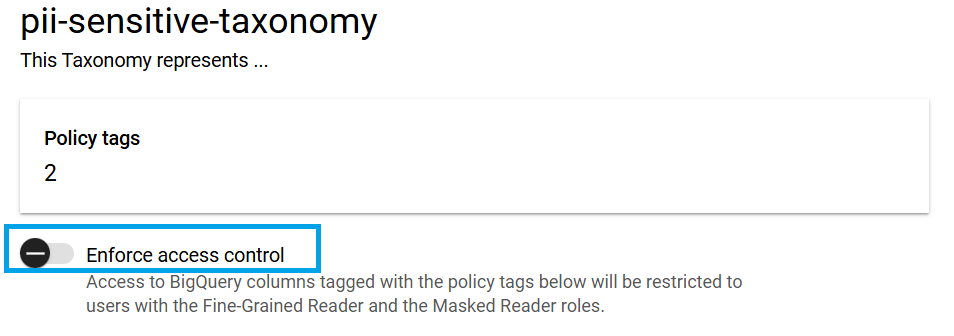
Step 5: Enable Access control
- If you have data masking rules then this will be automatically enabled, and you cannot disable it. So you must authorize users before enabling masking rules or enforcing access control.
- If you do not have data masking rules this will be manually enforced from the console as shown below. When you do not have masking rules but enforced access control, users who do not have access to policy tag will get an error if they try to query that field.
Step 6: Test data access with different type of users with different roles
- Sales user with maskedReader role to last 4 would see only last 4 of the driving licenses

- Analytics users with maskedReader to hash would see only the hashed version of driving license
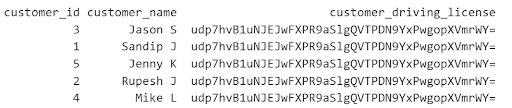
- Users with FineGrainedReader will be able to access both raw sensitive and non-sensitive data seamlessly

- Users without FineGrainedReader or maskedReader role will face error if they select a data column that has a policy tag
Error: Access Denied: BigQuery BigQuery: User has neither fine-grained reader nor masked get permission to get data protected by policy tag “pii-sensitive-taxonomy : driving_license” on column your_dataset.customer_data.customer_driving_license.
- Users without FineGrainedReader or maskedReader will be still able to access non-sensitive data that is not tagged
Step 6: Implement automated monitoring of policy tag lifecycle and for unauthorized tag removals or modifications, and remediation of potential security gaps.
Results and Benefits
- Enabled selective data access control at column level, allowing organizations to protect sensitive fields (like tax IDs, credit card numbers) while keeping non-sensitive data (like purchase history) accessible to appropriate users
- Strengthen regulatory compliance by providing granular control and audit trails for sensitive data access, helping meet both internal policies and external regulations (GDPR, CCPA, etc.)
- Ensured continuous compliance through automated monitoring of policy tag lifecycle, with real-time alerts for unauthorized tag removals or modifications, enabling prompt remediation of potential security gaps
- Enhanced customer and partner trust by demonstrating robust protection of their sensitive information through precise, documented data access controls
- Mitigated security risks by preventing unauthorized access to sensitive columns while maintaining business efficiency, replacing the traditional “all-or-nothing” access approach
- Improved operational efficiency by allowing data analysts to access necessary non-sensitive data without being blocked by overly broad security restrictions
Use phased approach for large data warehouses
- Prioritize Business Continuity: Implement changes in a phased manner to avoid significant service interruptions and perform thorough impact analysis of downstream applications and ELT pipelines
- Identify Stakeholders: Determine all users and service accounts that currently access sensitive data.
- Assess Data Access Patterns: Analyze existing data access methods, such as SELECT * queries and views, to identify potential impacts.
- Categorize Access Needs: Classify users, groups, and processes based on their required level of access to sensitive information.
- Implement Gradual Access Control: Before enabling full access control, grant fine-grained permissions to essential users and service accounts.
- Communicate Changes: Proactively inform affected teams about the upcoming changes and establish clear escalation procedures for incident reporting
Best Practices & Tips Taxonomy Design
- Create logical groupings based on sensitivity levels
- Use meaningful, standardised naming conventions
- Document taxonomy decisions and rationale
- Regularly audit policy tag assignments
- Implement least-privilege access principles
- Monitor and log access patterns
Conclusion
As organizations continue to navigate the complexities of data governance, implementing column-level security through GCP policy tags represents a significant leap forward in protecting sensitive information while maintaining operational efficiency. Our journey through implementing this solution at petabyte scale demonstrates that even large-scale data warehouses can successfully transition to granular access controls without disrupting business operations.
For organizations looking to enhance their data security posture, GCP’s policy tags offer a robust, scalable solution that aligns with modern data governance requirements. The phased approach we’ve outlined provides a practical roadmap for implementation, whether you’re managing thousands of tables or just beginning your data governance journey.
Contact Us to discuss your data governance needs with our experts and determine if GCP policy tagging and dynamic data masking aligns to your objectives.
What’s Next
For users who have already implemented policy tagging and looking for advanced policy tag management, here are some next steps to think of and apply as needed.
Technical Resources
Recommended Content

You Might Also Like



Data Analytics and AI